Migrating from SAS to Python or PySpark is a strategic shift from a proprietary, licensed ecosystem to an open-source, scalable environment. This transition typically involves moving to Python for smaller, single-machine workloads or PySpark for large-scale, distributed big data processing


Key Benefits of Migration
Cost Savings: Eliminates high SAS licensing fees; Python is free and open-source.
Scalability: PySpark enables distributed processing across clusters (e.g., Databricks, AWS EMR), overcoming SAS's single-node limitations.
Modern Ecosystem: Seamless integration with modern AI, machine learning, and cloud-native data tools.
Talent Acquisition: It is often easier to hire developers with Python skills than to up-skill new hires in SAS
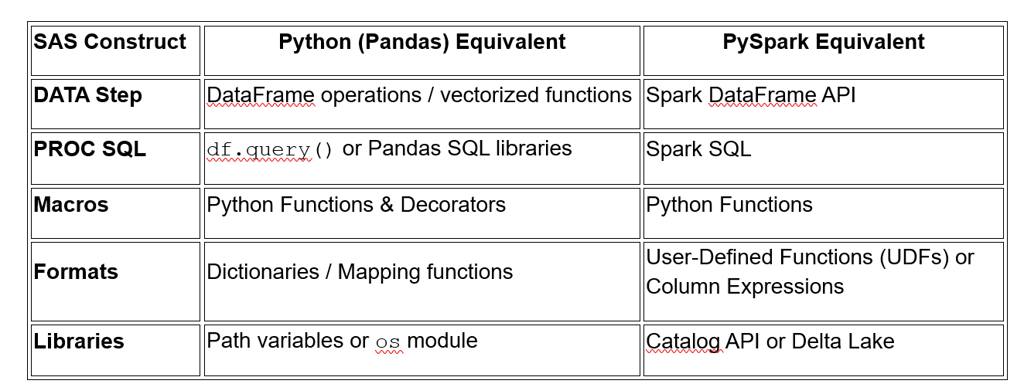
Mapping SAS Constructs to Python/PySpark
Successful migration requires translating procedural logic into a functional, distributed mindset.
Critical Challenges
Paradigm Shift: Moving from SAS’s procedural approach to PySpark's distributed computing model requires a different optimization mindset (e.g., understanding repartition() vs. coalesce()).
Data Validation: Ensuring row-by-row and column-by-column parity between legacy SAS outputs and new Python/PySpark outputs is essential.
Missing Features: SAS includes built-in statistical procedures (PROCs) that may require importing multiple specific Python libraries (e.g., Scipy, Statsmodels) to replicate.